3 DDCond Conditions Store and Slices
The interface allows tools to work with various conditions data stores. DDCond provides an efficient implementation of such a store, which is described in the following chapters.
3.1 Data Organization
The basic assumption of the DDCond conditions store to optimize the access and the management of conditions data can be very simply summarized: it is assumed, that groups of data items exist, which have a common interval of validity. In other words: given a certain event, valid or invalid conditions can quickly be identified by checking the so called ”interval of validity” of the entire group with the time stamp of the event. This interval of validity defines the time span for which a given group of processing parameters is valid. It starts and ends with a time stamp. The definition of a time stamp may be user defined and not necessarily resemble to values in seconds or fractions thereof. Time stamps could as well be formulated as an interval of luminosity sections, run numbers, fill numbers or entire years.
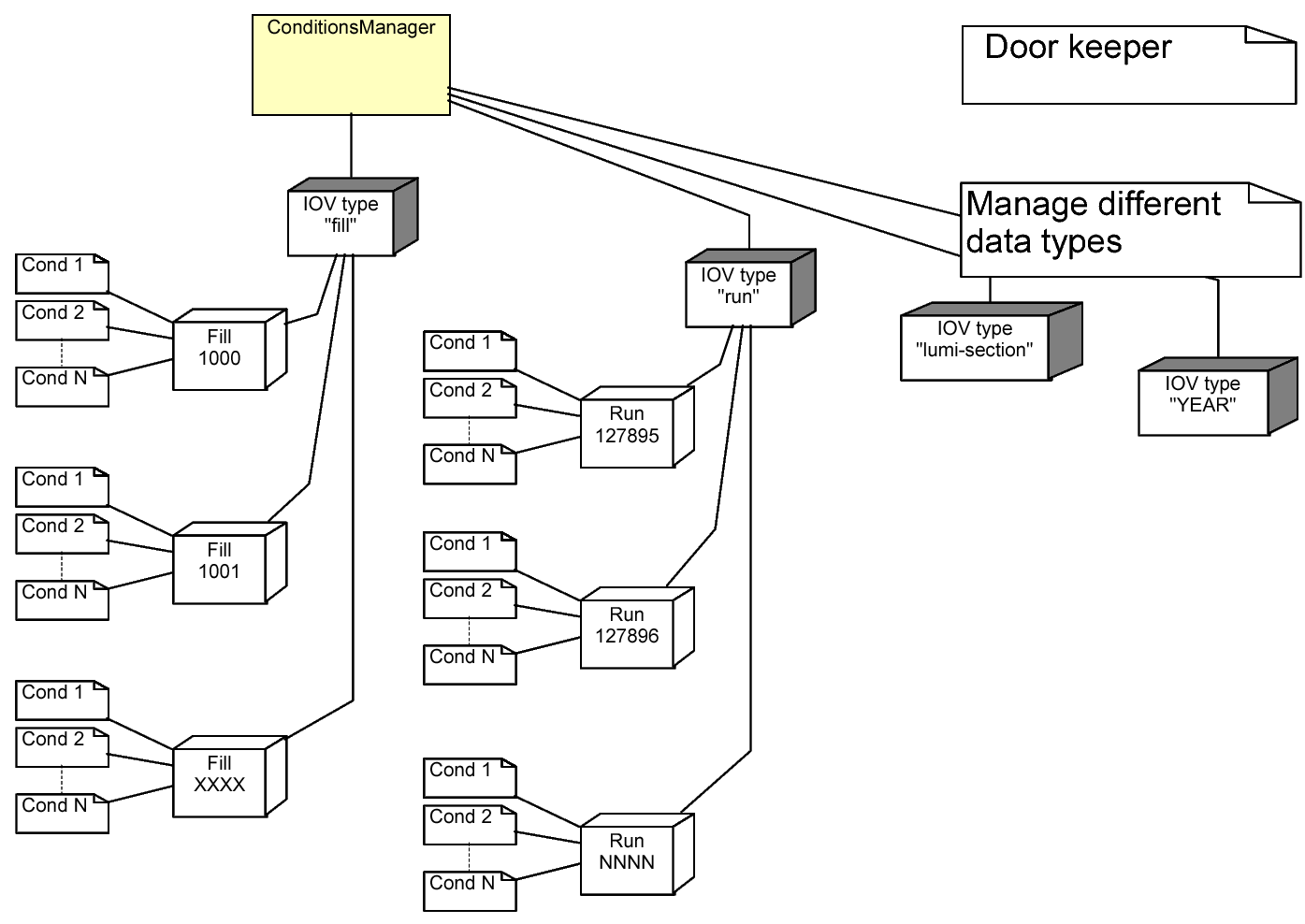
Groups of parameters associated to certain intervals of validity can be very effectively managed if pooled together according to the interval of validity. This of course assumes that each group contains a significant number of parameters. If each of these pools only contains one single value this would not be an efficient.
This assumption is fundamental for this approach to be efficient. If the data are not organized accordingly, the caching mechanism implemented in DDCond will still work formally. However, by construction it cannot not work efficiently. Resources both in CPU and memory would be wasted at run-time. The necessity to properly organize the conditions data becomes immediately evident in Figure 1: Users can organize data according to certain types, These types are independently managed and subdivided into pools. Each of these pools manages a set of conditions items sharing the same interval of validity.
The internal organization of the conditions data in DDCond is entirely transparent to the user. The description here is contained for completeness and for the understanding of the limitations of the implemented approach. If different requirements or access patterns concerning the access to conditions data arise, it should though be feasible to implement these fairly straight forward using a suited approach.
3.2 Slice Configuration and Data Access
As defined in section 1.2, the conditions slice is the main entity to project conditions suitable to process a given particle collision (see DDCond/ConditionsContent.h for details). Figure ?? shows the data content of a conditions slice. As shown also in Figure 3, there are several steps to be performed before a conditions slice is ready to be used:
- Create the conditions data slice.
- Setting up the data content of the slice by attaching an object of type .
- Preparing the conditions data slice.
- Using the conditions data slice.

The (see DDCond/ConditionsSlice.h for details) is a simple object, which contains load addresses to identify persistent conditions within the database/persistent schema used and a set of dependency rules to compute the corresponding derived conditions.
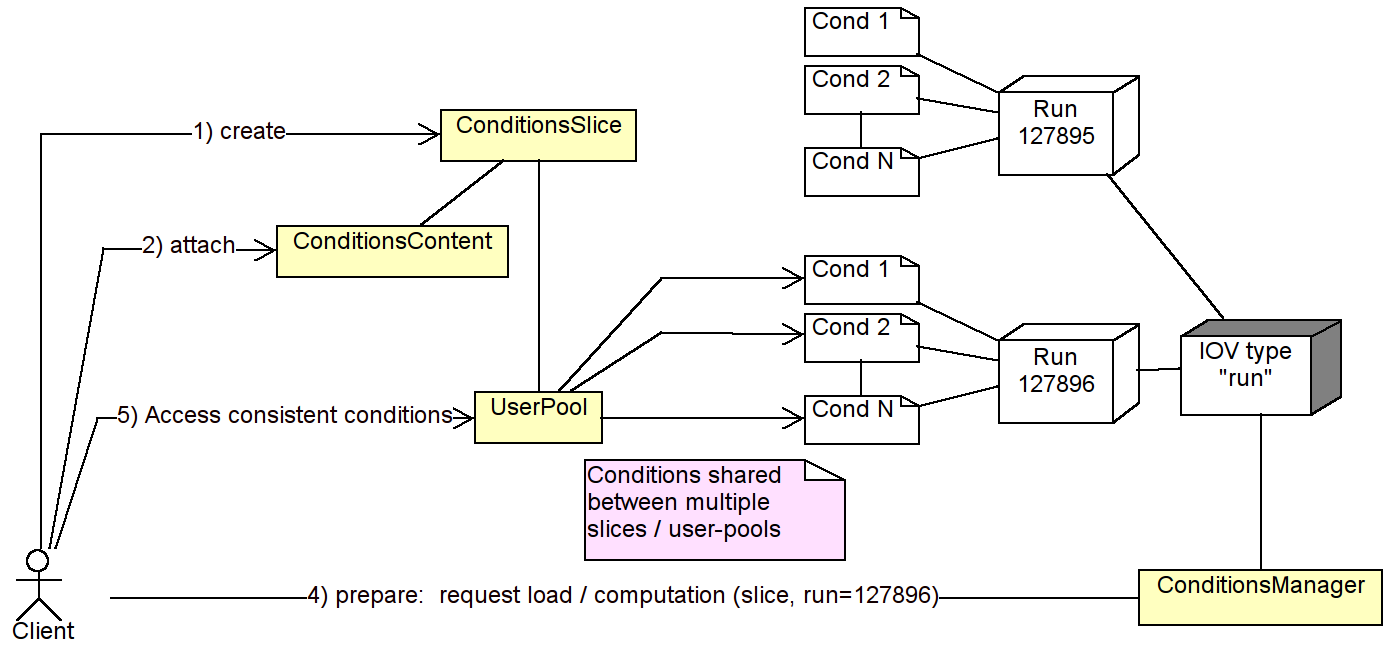
The holds a consistent set of conditions valid for a given interval of validity, which is the intersection of the intervals of validity of all contained conditions. The has the following consequences for the client when using a prepared :
-
objects are prepared by the client framework. Specific algorithms and other code fragments developed by physicist users should not deal with such activities. In multi-threaded applications the preparation of a may be done in a separate thread.
-
Once prepared, the slice nor the contained conditions may be altered. All contained conditions must be considered read-only.
-
Since the slice is considered read-only, it can be used by multiple clients simultaneously. In particular, multiple threads may share the same slice.
-
A may only be re-used and prepared according to a different interval of validity once no other clients use it.
-
At any point of time any number of objects may be present in the client framework. There is no interference as long as the above mentioned requirements are fulfilled.
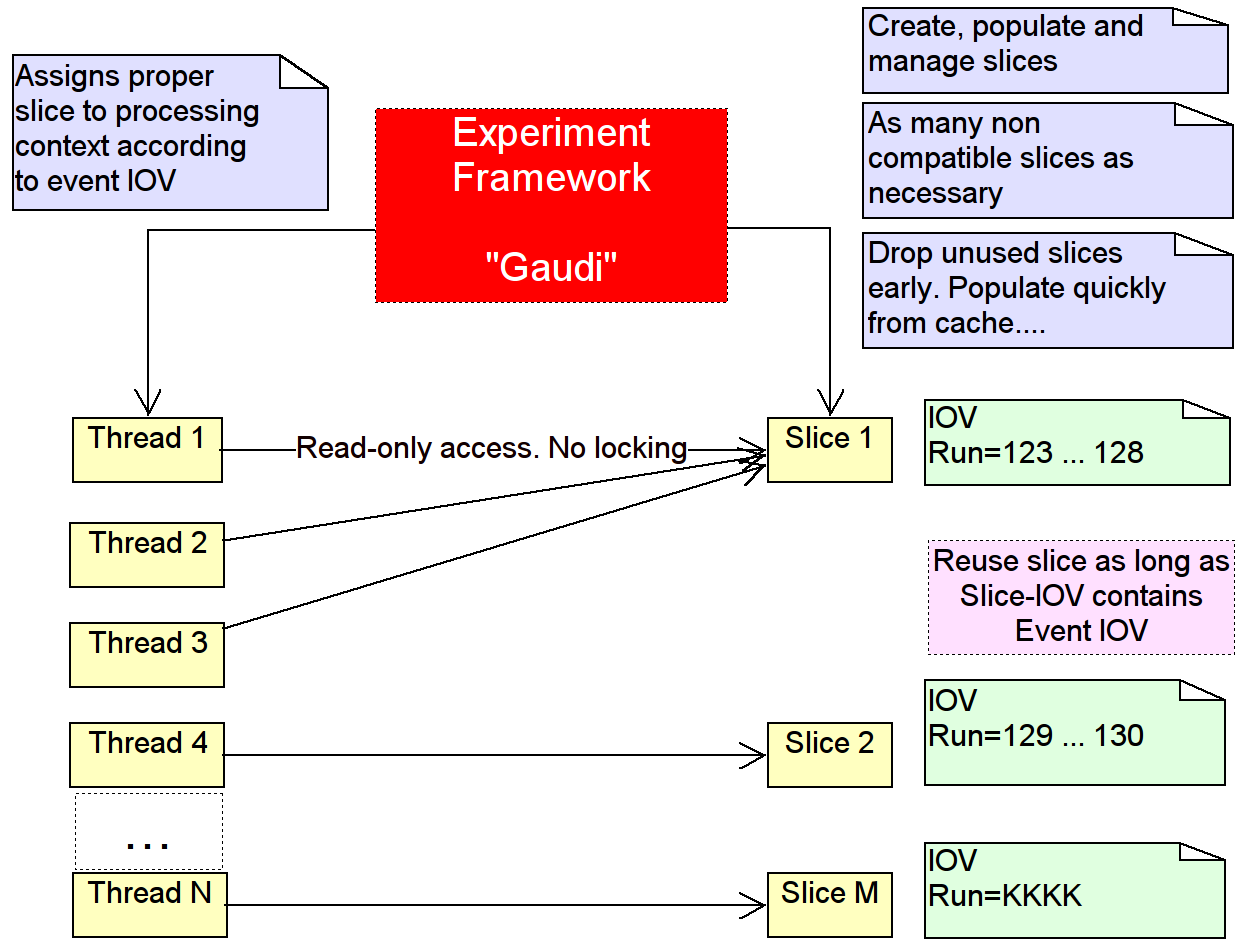
The fact that multiple instances of the conditions slices may be present as well as the fact that the preparation of slices and their use is strictly separated makes then ideal for the usage within multi-threaded event processing frameworks. As shown in figure 4, the following use cases can easily be met:
-
Multiple threads may share the same slice while processing event data (thread 1-3) as long as the time stamp of the event data processed by each thread is contained in the interval of validity of the slice.
-
At the same time another thread may process event data with a different time stamp. The conditions for this event were prepared using another slice (thread 4-N).
3.3 Loading Conditions Data
The loading of conditions data is highly experiment specific. Different access patterns and load implementations (single threaded, multi-threaded, locking etc.) make it close to impossible to implement any solution fitting all needs. For this reason the loading of conditions is deferred to an abstract implementation, which is invoked during the preparation phase of a conditions slice if the required data are not found in the conditions cache. This data loader interface (see ConditionsDataLoader.h for details), receives all relevant callbacks from the framework to resolve missing conditions and pass the loaded objects to the framework for the management. The callback to be implemented by the framework developers are:
/// Interface for a generic conditions loader /** * Common function for all loader. */ class ConditionsDataLoader : public NamedObject, public PropertyConfigurable { typedef Condition::key_type key_type; typedef std::map<key_type,Condition> LoadedItems; typedef std::vector<std::pair<key_type,ConditionsLoadInfo*> > RequiredItems; public: .... /// Load a number of conditions items from the persistent medium according to the required IOV virtual size_t load_many( const IOV& req_validity, RequiredItems& work, LoadedItems& loaded, IOV& combined_validity) = 0; };
The arguments to the callback contain the necessary information to retrieve the requested items.